辉羲智能与上海交大合研成果入选电子设计自动化顶会DAC 2023
近日,电子设计自动化领域顶会DAC 2023正式放榜,云九资本投资企业辉羲智能与上海交通大学合作发表的两篇技术论文成功入选。
DAC(Design Automation Conference,CCF-A类)一直被公认是设计自动化领域的顶级会议,在国际半导体技术界享有重要地位和广泛影响。大会每年吸引全球众多工业界和学术界人士参与成果发布和技术讨论,近年论文接收率在23%左右,以专业、权威和高含金量著称。
以下是入选的两篇论文分享:
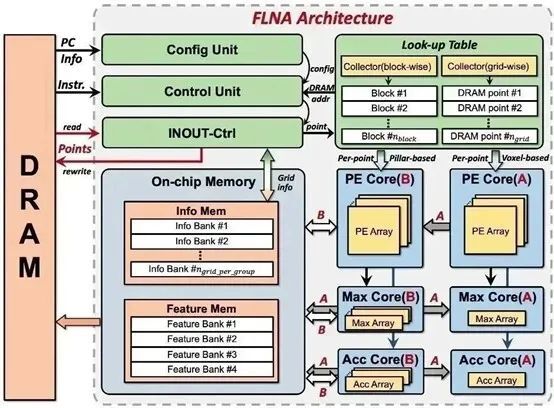
FLNA:通过数据流解耦方法最大化利用点云空间稀疏性降低计算复杂度和存储需求,大幅度降低定制化加速器硬件资源需求
激光雷达是近年来快速发展的智能驾驶系统中不可或缺的重要传感器,其采集到点云(Point Cloud)的数据为感知网络提供了细致的空间物体信息。由于点云数据具有空间稀疏性和不规则分布特性,普遍选择点云特征学习网络(Feature Learning Network)将其转换为规则化的三维体素(voxel)来提取特征。然而特征学习网络需要庞大的内存和计算开销,对终端部署造成巨大的挑战。
针对上述问题,辉羲和上海交大研究团队提出了一种数据流解耦方法,在不影响计算精度的情况下,将体素内逐点和整体特征运算解耦,深入利用空间稀疏性来消除冗余计算量,实现了超过95%的存储开销降低。基于以上方法,团队设计了一款全流水的特征学习网络加速器(FLNA)。FLNA通过计算单元复用实现了对多种常用的特征学习网络类型的支持,同时可对点云数据参数进行灵活配置。针对不规则存储读写问题,团队提出了特殊的片上数据排布策略,最大化提高片上SRAM带宽利用率。实验表明,与当前近似工作相比,FLNA第一次支持了更加复杂的基于体素的特征学习网络,并且可以在更高的能效下实现2.1倍的加速比。
COSA: 探索Transformer固有计算特征,利用混合数据复用和多种融合技术,设计高能效高利用率低延迟的加速器
近年来,Transformer神经网络在计算机视觉、自然语言处理方面表现出超过传统CNN、RNN神经网络的优越性能,但其巨大的参数量和计算量对硬件平台的支持提出了新的挑战。许多学者从软硬件协同的角度出发,试图通过剪枝、模型压缩等方法稀疏化网络,并设计相应的硬件加速器。然而稀疏化的方法需要繁琐的调参和重训练过程以达到精度要求,辉羲和上海交大研究团队从新的维度出发,指出分析并利用Transformer网络固有的数据流特征,是设计Transformer加速器的另一个关键技术,此工作也是该领域最早的研究之一。
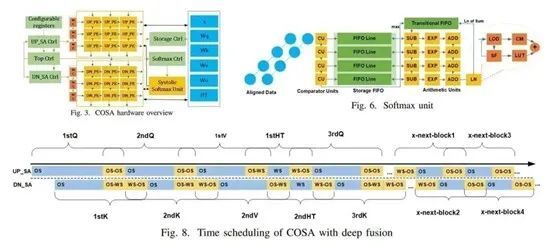
研究团队挖掘了Transformer的核心算子,多头注意力机制中的密集矩阵乘、密集部分积、丰富并行度、非线性算子夹杂等计算特征,从固有数据流角度出发设计了COSA (Co-Operative Systolic Arrays) 加速器。其计算单元可配置,可动态支持权重/输出固定的数据复用方式,并通过头融合(fused head),部分积融合(fused product),深度融合(deep fusion)技术以及先进的softmax单元设计,进一步提高PE单元的利用率和吞吐率,降低延迟和访存。相较于以往的设计,COSA可达到2.95-28.82的加速比,以及实现高达97.4%的PE利用率。
论文标题:COSA: Co-Operative Systolic Arrays for Multi-head Attention Mechanism in Neural Network using Hybrid Data Reuse and Fusion Methodologies