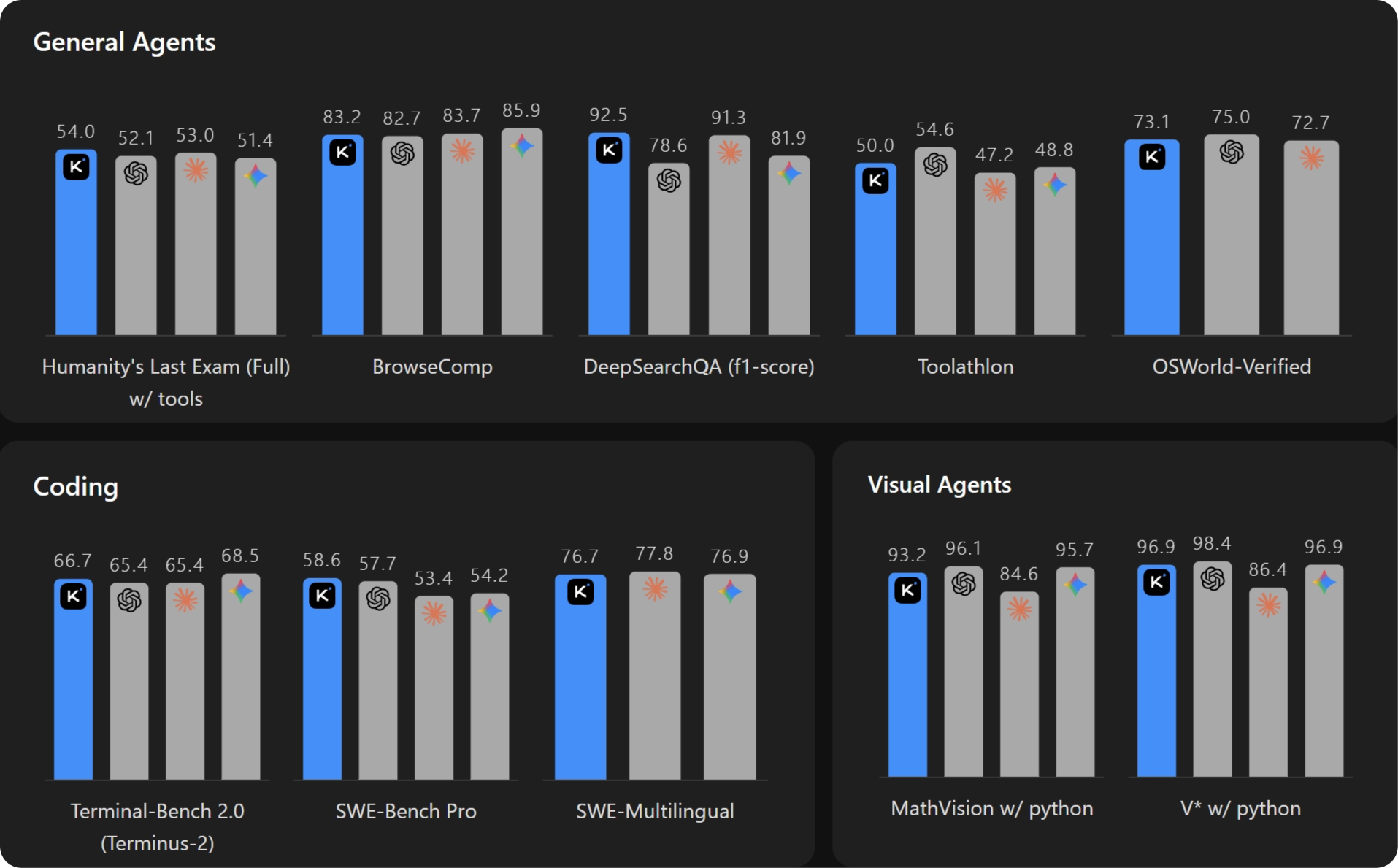
On April 20, Kimi (Moonshot AI), a leading AI technology company and a Sky9 Capital portfolio company, released and open-sourced their latest model, Kimi K2.6, featuring state-of-the-art coding, long-horizon execution, and agent swarm capabilities.
Long-Horizon Coding
Kimi K2.6 shows strong improvements in long-horizon coding tasks, with reliable generalization across programming languages (e.g., Rust, Go, and Python) and tasks (e.g., front-end, devops, and performance optimization). On Kimi Code Bench, Kimi’s internal coding benchmark covering diverse complicated end-to-end tasks, Kimi K2.6 demonstrates significant improvements over Kimi K2.5.

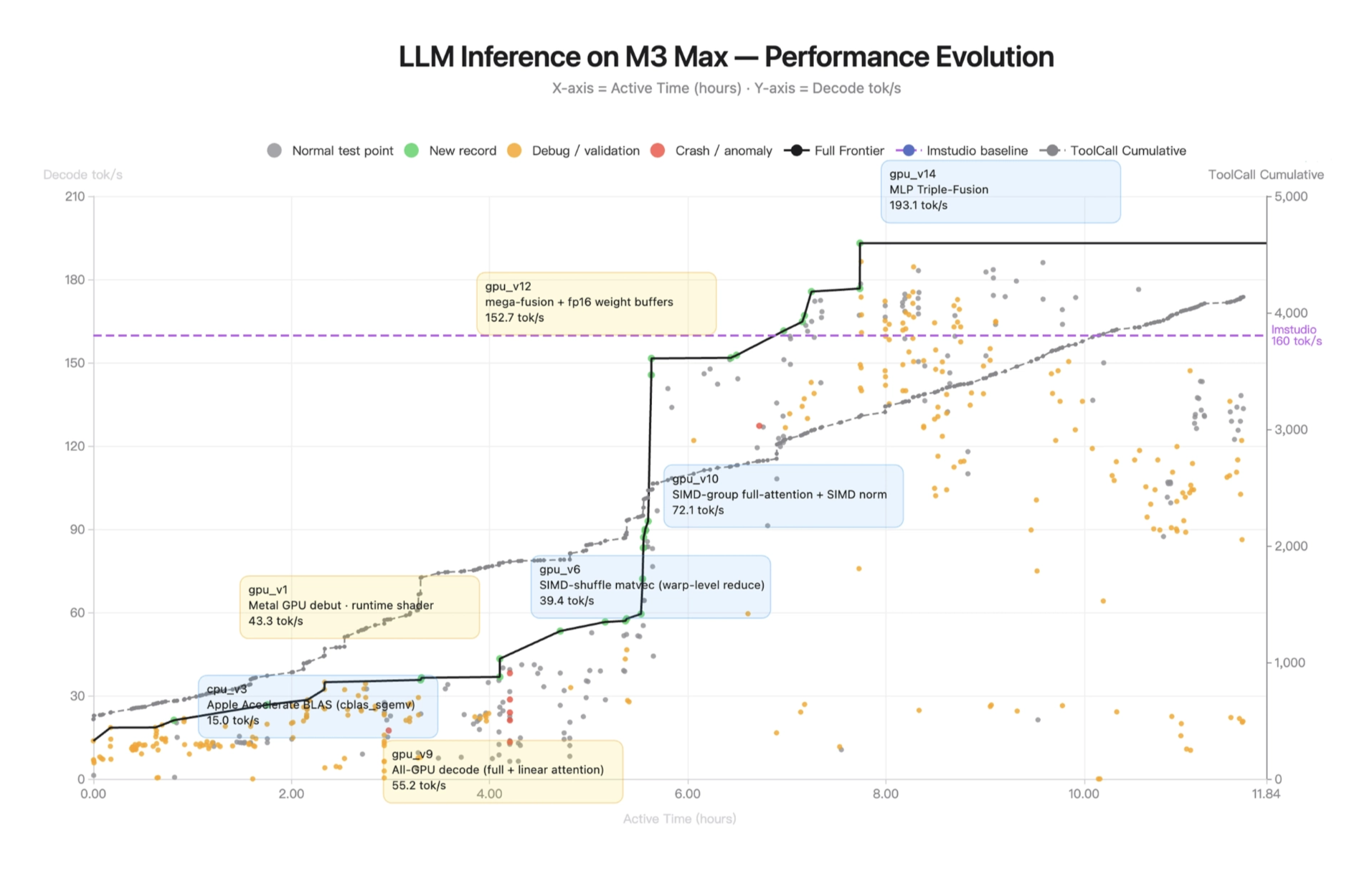
Kimi K2.6 successfully downloaded and deployed the Qwen3.5-0.8B model locally on a Mac. By implementing and optimizing model inference in Zig—a highly niche programming language—it demonstrated exceptional out-of-distribution generalization. Across 4,000+ tool calls, over 12 hours of continuous execution, and 14 iterations, Kimi K2.6 dramatically improved throughput from ~15 to ~193 tokens/sec, ultimately achieving speeds ~20% faster than LM Studio.
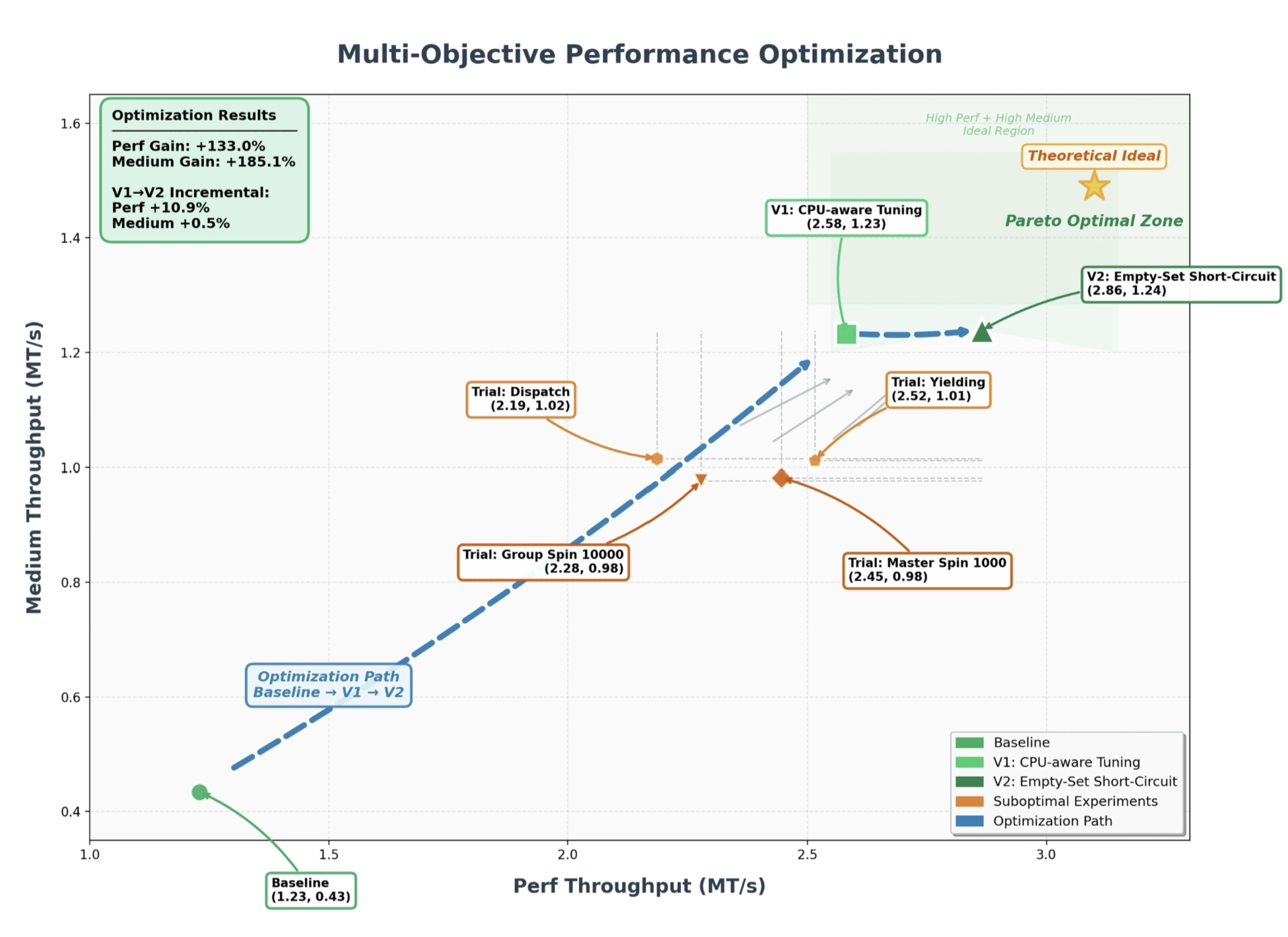
Kimi K2.6 autonomously overhauled exchange-core, an 8-year-old open-source financial matching engine. Over a 13-hour execution, the model iterated through 12 optimization strategies, initiating over 1,000 tool calls to precisely modify more than 4,000 lines of code. Acting as an expert systems architect, Kimi K2.6 analyzed CPU and allocation flame graphs to pinpoint hidden bottlenecks and boldly reconfigured the core thread topology (from 4ME+2RE to 2ME+1RE). Despite the engine already operating near its performance limits, Kimi K2.6 extracted a 185% medium throughput leap (from 0.43 to 1.24 MT/s) and a 133% performance throughput gain (soaring from 1.23 to 2.86 MT/s).
In beta tests, K2.6 performs well on long-horizon coding tasks in enterprise evaluations (randomly ordered):

Got an early look at K2.6 and ran it through Hermes Agent. Tool calling and agentic loops feel noticeably tighter, coding is a clear step up, and the creative range surprised us. We’re super excited about running a hackathon with Kimi on creativity. Kimi team continues to beat expectations!

Kimi K2.6 raises the bar for open-source models. It excels in coding and especially for agentic tools like OpenClaw and Hermes. In early testing, it sustains long multi-step sessions with impressive stability. It will work all of Ollama’s integrations out of the box, and we’re excited to see what developers build with it.

Kimi K2.6’s evolution is impressive. It excels on coding tasks at a level comparable to leading closed source models, and offers strong tool calling quality due to its deep understanding of third party frameworks. Kimi K2.6’s excellent reliability makes it a great choice for complex and long-horizon engineering tasks.

Kimi K2.6 demonstrates significant improvements over K2.5 in internal evaluations conducted by CodeBuddy: code generation accuracy increased by 12%, long-context stability improved by 18%, and tool invocation success rate reached 96.60%. Its stronger reasoning capabilities and more consistent output quality provide robust support for ensuring a reliable user experience in CodeBuddy WorkBuddy.

Kimi K2.6 sets a new level for open-sourced models, especially in long-horizon, agent-style coding workflows. It handles complex, multi-step tasks with stronger instruction following and consistently high code quality. We’ve seen it sustain extended coding sessions with remarkable stability, far beyond typical models. It also surfaces deep, non-obvious bugs that would normally take significant developer time to uncover. Overall, K2.6 sets a new bar for reliable coding.

In a no-code environment, AI has to handle every edge case. There’s no developer to step in when something doesn’t work as expected. K2.6 is noticeably more effective than K2.5 at navigating nuanced API behaviors and recovering when things break, and it runs longer-horizon tasks before hitting a wall. We’ve seen a real improvement in getting users from idea to deployment compared to K2.5.

We are thrilled to see another leap in open source models with Kimi K2.6 release, which marks a significant advancement for high-stakes, agentic workflows. The most impactful improvements lie in its long-horizon reliability and instruction following. K2.6 excels at maintaining architectural integrity over extended coding sessions, making it a stable foundation for autonomous agent pipelines, like all the “claws”. It demonstrates a measurable leap over K2.5 in long-context tasks, achieving state-of-the-art performance in complex reasoning.

Kimi K2.6 delivered a strong performance in Qoder’s internal evaluations, showing significant progress over K2.5. Specifically, there has been a notable increase in the frequency of tool calling and model invocations, reflecting a substantial boost in the model’s proactivity and intelligence during task execution. This heightened initiative in tool calling enables the model to more actively grasp developer intent and automatically complete context, thereby minimizing user interruptions and wait times.

K2.6 shows major gains over K2.5 on the capabilities our developers care about most: we’re seeing more than 50% improvement on our Next.js benchmark, putting it among the top-performing models on the platform. Combined with its cost-performance ratio, it’s a compelling option for agentic coding and front-end generation through AI Gateway. We’re excited to offer it to our developer community.

K2.6 offers SOTA-level performance at a fraction of the cost. It’s tremendously good at long-context tasks across the codebase, as well as the day-to-day work needed to support an always-on agent like KiloClaw.

What impressed us most about K2.6 is its surgical precision in large codebases. When an initial path is blocked, it is strong at pivoting intelligently: following existing architectural patterns, finding hidden related changes, and keeping fixes scoped to the real problem. That kind of focused adaptability helps Augment Code reduce wasted cycles and deliver faster, more cost-effective agentic coding for enterprise-scale engineering work.

K2.6 is a clear improvement on K2.5 on both our benchmarks (+15%) and in side-by-side comparisons. It seems to have better instruction following, more thorough exploration and reasoning, and less likely to make coding errors or use hacks.

K2.6 is a clear improvement on K2.5 on both our benchmarks (+15%) and in side-by-side comparisons. It seems to have better instruction following, more thorough exploration and reasoning, and less likely to make coding errors or use hacks.

Within OpenCode, Kimi K2.6 proves to be exceptionally reliable. Its approach to task decomposition and tool calling is both steady and consistent. With a sharper grasp of task requirements and more streamlined multi-step operations, it effectively minimizes repetitive overhead, resulting in a smoother, more trustworthy end-to-end experience.
Coding-Driven Design
Based on the strong coding capabilities, Kimi K2.6 can turn simple prompts into complete front-end interfaces, generating structured layouts with deliberate design choices such as aesthetic hero sections, as well as interactive elements and rich animations, including scroll-triggered effects. With strong proficiency in leveraging image and video generation tools, Kimi K2.6 supports the generation of visually coherent assets and contributes to higher-quality, more salient hero sections.
Moreover, Kimi K2.6 expands beyond static frontend development to simple full-stack workflows—spanning authentication to user interaction to database operations for lightweight use cases like transaction logging or session management.
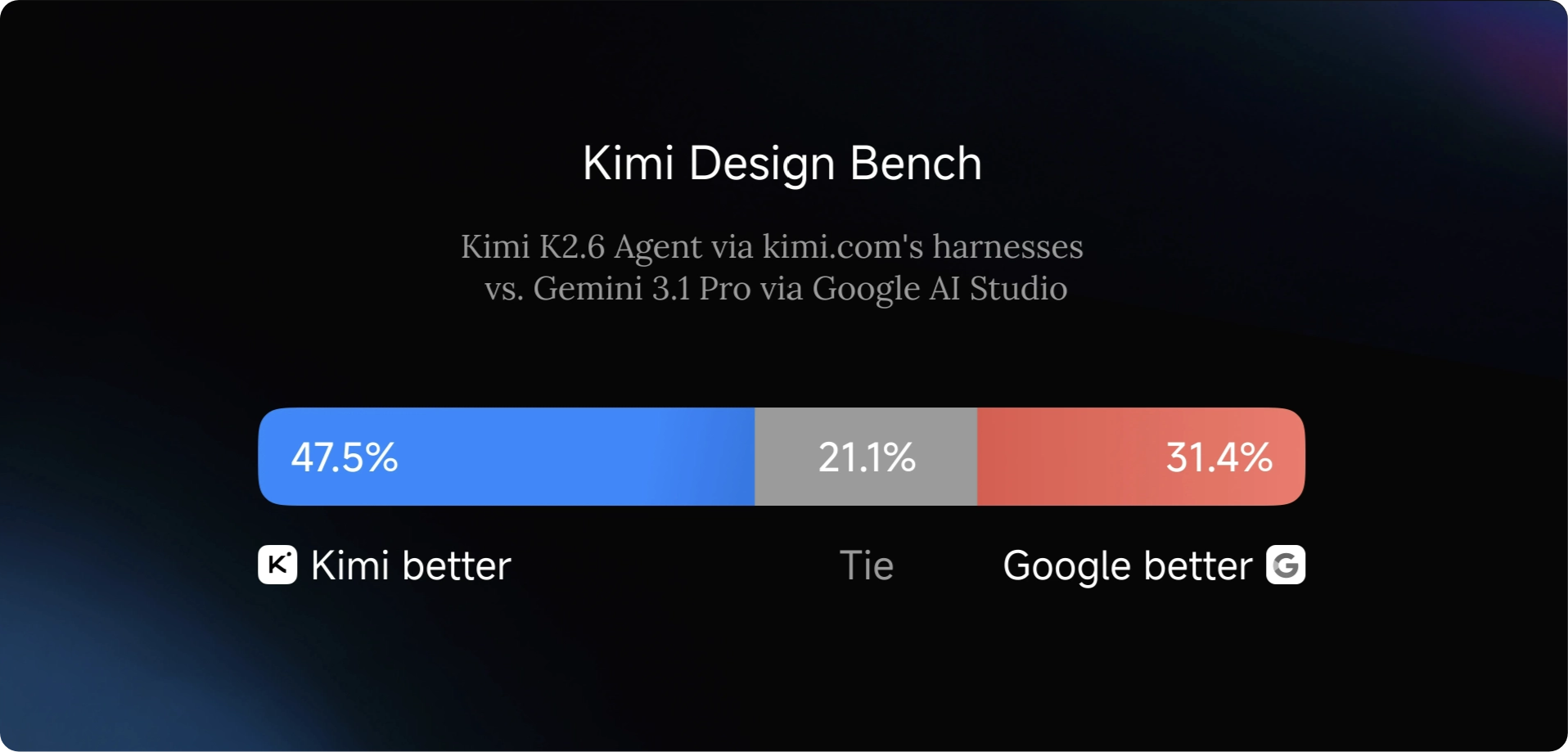
Kimi established an internal Kimi Design Bench, organized into four categories: Visual Input Tasks, Landing Page Construction, Full-Stack Application Development, and General Creative Programming. In comparison with Google AI Studio, Kimi K2.6 shows promising results and performs well across these categories.
Below are examples generated by K2.6 Agent from a single prompt, with preconfigured harnesses and tools:
Aesthetic: Beautiful front-end design with rich interaction
Functionality: With built-in database and authentication
Tool use: Use image/video gen tools to create a polished website
Agent Swarms, Elevated
Scaling out, not just up. An Agent Swarm dynamically decomposes tasks into heterogeneous subtasks executed concurrently by self-created domain-specialized agents.
Based on the K2.5 Agent Swarm research preview, Kimi K2.6 Agent Swarm demonstrates a qualitative leap in the agent swarm experience. It seamlessly coordinates heterogeneous agents to combine complementary skills: broad search layered with deep research, large-scale document analysis fused with long-form writing, and multi-format content generation executed in parallel. This compositional intelligence enables the swarm to deliver end-to-end outputs—spanning documents, websites, slides, and spreadsheets—within a single autonomous run.
The architecture scales horizontally to 300 sub-agents executing across 4,000 coordinated steps simultaneously, a substantial expansion from K2.5’s 100 sub-agents and 1,500 steps. This massive parallelization fundamentally reduces end-to-end latency while significantly enhancing output quality and expanding the operational boundaries of Agents swarms.
It can also turn any high-quality files such as PDFs, spreadsheets, slides, and Word documents into Skills. Kimi K2.6 captures and maintains the documents’ structural and stylistic DNA, enabling you to reproduce the same quality and format in future tasks.
Here are some examples:
Designed and executed 5 quantitative strategies across 100 global semiconductor assets, deriving McKinsey-style PPT as reusable skills, and delivering detailed modeling spreadsheets and a full executive presentation.
Turned a high-quality astrophysics paper with rich visual data into a reusable academic skill, deriving its reasoning flow and visualization methods, and produced a 40-page, 7,000-word research paper, a structured dataset with 20,000+ entries, and 14 astronomy-grade charts.
Based on the uploaded CV, K2.6 spawned 100 sub-agents to match 100 relevant roles in California, delivering a structured dataset of opportunities and 100 fully customized resumes.
Identified 30 retail stores in Los Angeles without official websites from Google Maps, and generated high-converting landing pages for each, demonstrating opportunity discovery and end-to-end execution.
Proactive Agents
K2.6 demonstrates strong performance in autonomous, proactive agents such as OpenClaw and Hermes, which operate across multiple applications with continuous, 24/7 execution.
Unlike simple chat-based interactions, these workflows require AI to proactively manage schedules, execute code, and orchestrate cross-platform operations as a persistent background agent.
Kimi’s RL infra team used a K2.6-backed agent that operated autonomously for 5 days, managing monitoring, incident response, and system operations, demonstrating persistent context, multi-threaded task handling, and full-cycle execution from alert to resolution. Here is K2.6’s worklog (anonymized to remove sensitive information):
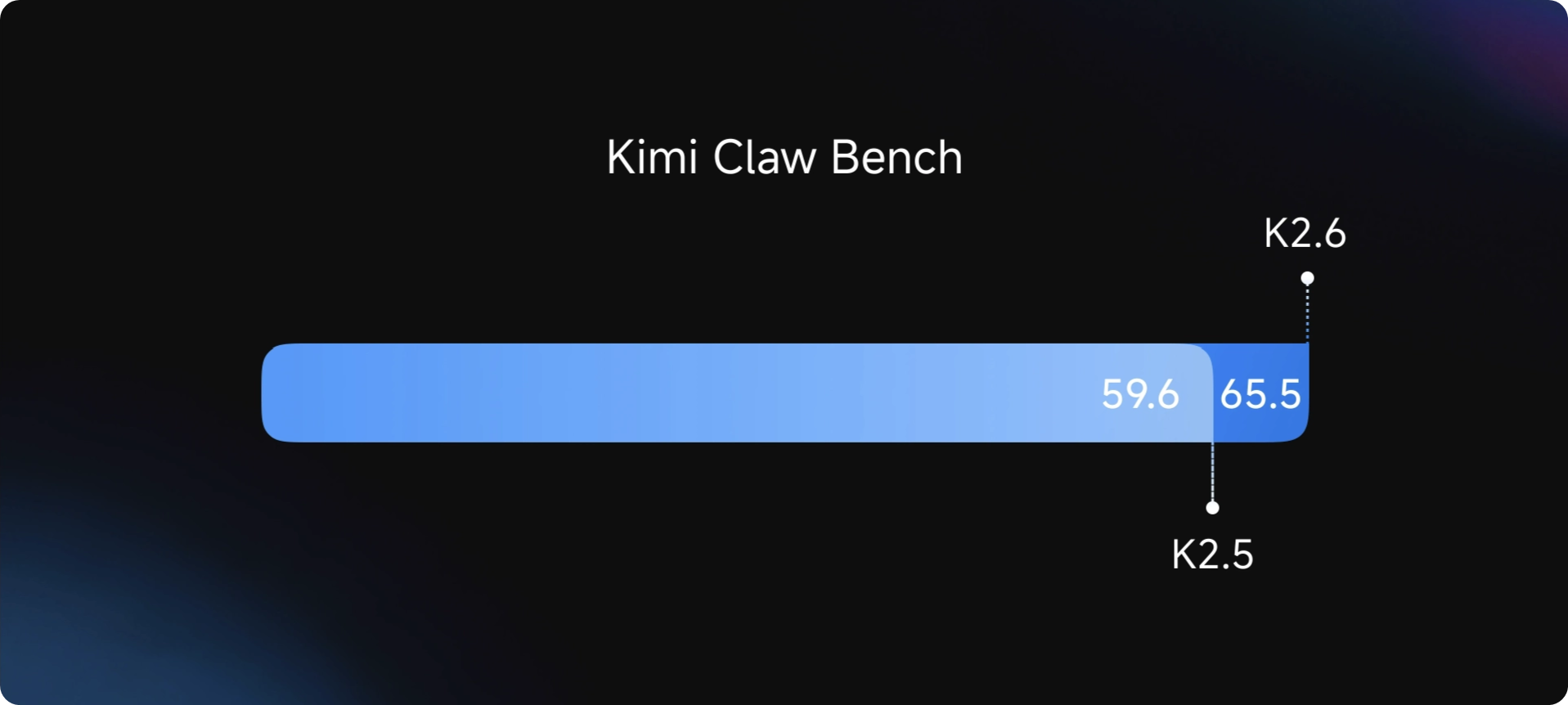
Kimi K2.6 delivers measurable improvements in real-world reliability: more precise API interpretation, stabler long-running performance, and enhanced safety awareness during extended research tasks.
Performance gains are quantified by our internal Claw Bench, the evaluation suite spanning five domains: Coding Tasks, IM Ecosystem Integration, Information Research & Analysis, Scheduled Task Management, and Memory Utilization. Across all metrics, Kimi K2.6 significantly outperforms Kimi K2.5 in task completion rates and tool invocation accuracy—particularly in workflows requiring sustained autonomous operation without human oversight.
Bring Your Own Agents
Building upon Kimi K2.6’s robust orchestration capabilities, Kimi K2.6 extends user’s proactive agents to Claw Groups as a research preview—a new instantiation of the Agent Swarm architecture.
Claw Groups embrace an open, heterogeneous ecosystem: Multiple agents and humans operate as true collaborators. Users can onboard agents from any device, running any model, each carrying their own specialized toolkits, skills and persistent memory contexts. Whether deployed on local laptops, mobile devices, or cloud instances, these diverse agents integrate seamlessly into a shared operational space.
At the center of this swarm, Kimi K2.6 serves as an adaptive coordinator. It dynamically matches tasks to agents based on their specific skill profiles and available tools, optimizing for capability fit. When an agent encounters failure or stalls, the coordinator detects the interruption, automatically reassigns the task or regenerates subtasks, and actively manages the full lifecycle of deliverables—from initiation through validation to completion.
The K2.6-powered agents in Claw Groups were also part of the process. The team has been dogfooding our own agent marketing team by refining human–agent workflows in practice. Using Claw Groups, it runs end-to-end content production and launch campaigns, with specialized agents like Demo Makers, Benchmark Makers, Social Media Agents, and Video Makers working together. K2.6 coordinates the process, enabling agents to share intermediate results and turn ideas into consistent, fully packaged deliverables.
We are moving beyond simply asking AI a question or assigning AI a task, and entering a phase where human and AI collaborate as genuine partners—combining strengths to solve problems collectively. Claw Groups marks its latest efforts toward a future where the boundaries between “my agent,” “your agent,” and “our team” dissolve seamlessly into a collaborative system.