From March 16 to 19, the global AI event NVIDIA GTC was held in San Jose, California. At 11:00 AM local time on March 17, Zhilin Yang, founder of Moonshot AI, a Sky9 Capital portfolio company, delivered a keynote titled How We Scaled Kimi K2.5. As the only founder of an independent Chinese LLM company invited to speak, he provided the first comprehensive disclosure of the technical roadmap behind Kimi K2.5.
Author: Jiang Yu, Editor: Yun Peng, Source: 智东西
On March 16, Moonshot AI published a new paper previewing a key module of their next-generation model: Attention Residuals (AttnRes). The core of this paper is a redesign of the residual connection, one of the most fundamental structures in large models that has long been accepted by default.

The work quickly drew attention from the global AI community. Elon Musk called it “impressive”, while Andrej Karpathy, former OpenAI VP of Research and co-founder, stated bluntly that people’s understanding of the seminal Transformer paper, Attention is All You Need, might still be insufficient.
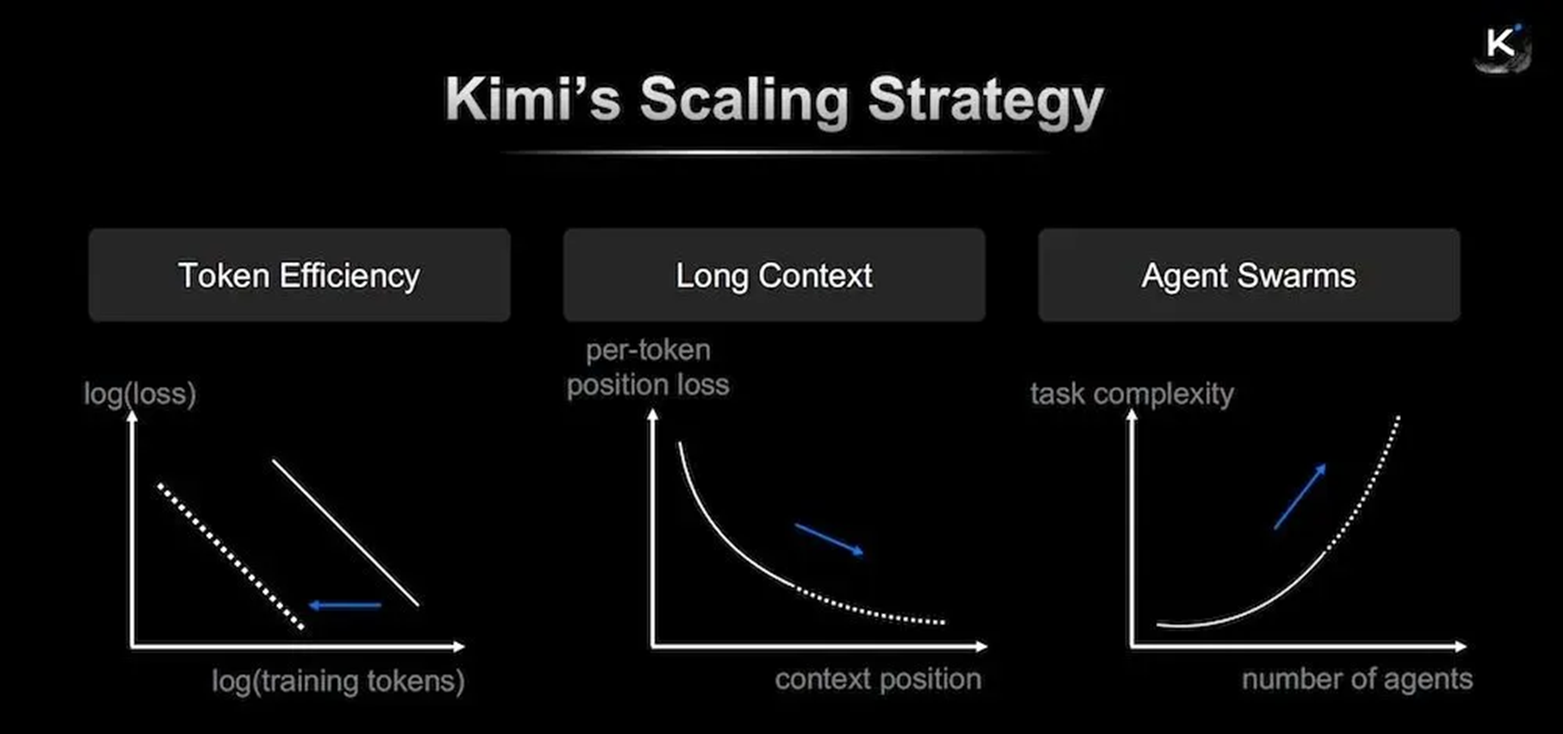
In this GTC keynote, Zhilin Yang placed this research back into Kimis more complete technical framework, providing a more systematic roadmap. He summarized the evolutionary logic of Kimi K2.5 as the resonance of three dimensions: Token Efficiency, Long Context, and Agent Swarms.
According to Yang, current scaling is no longer about the simple accumulation of resources. Instead, it requires finding scale effects simultaneously in computational efficiency, long-term memory, and automated collaboration. If the technical gains from these three dimensions can be multiplied, the model will exhibit intelligence levels far exceeding the status quo.
This also marks the first time Moonshot AI has systematically disclosed this technical roadmap since the release of Kimi K2.5 in late January.
Yang proposed that many technical standards currently used by the industry are essentially products from eight or nine years ago and are gradually becoming bottlenecks for scaling. Around this issue, the Kimi team chose to start with three basic modules—optimizer, attention mechanism, and residual connections—to reconstruct them one by one and continuously open-source them.
1. Rewriting the Training Base: MuonClip, Pushing Token Efficiency to 2x That of AdamW
The Kimi team placed their first emphasis on Token Efficiency, with Yang focusing the discussion on the optimizer issue during his speech.
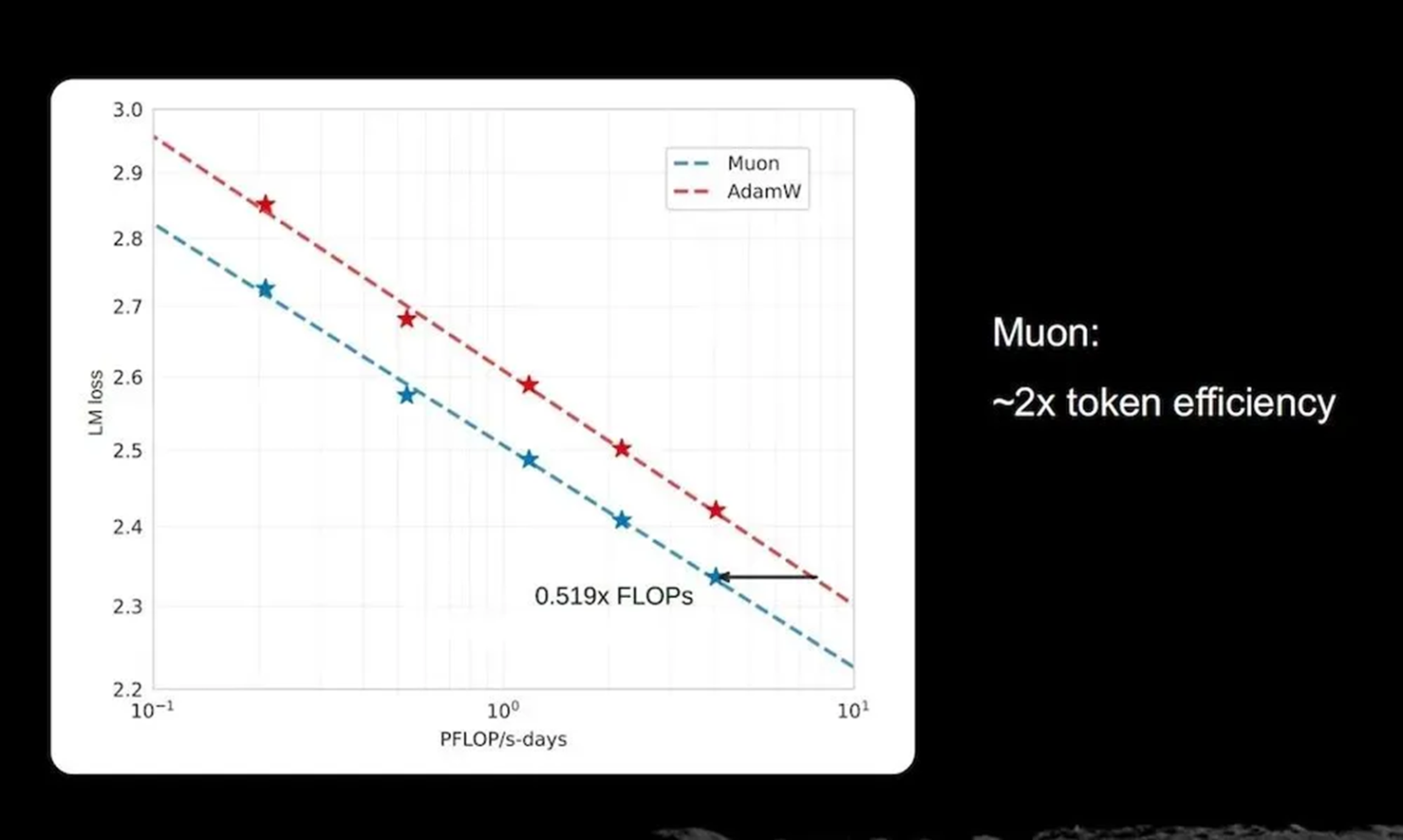
He mentioned that since 2014, the Adam optimizer has been the industrys default choice, but in ultra-large-scale training, alternatives with higher token efficiency have become an important direction. The Kimi team verified through experiments that the Muon optimizer possesses a significant advantage in token efficiency. Under similar computational budgets, it can convert training tokens into model capability at twice the efficiency.
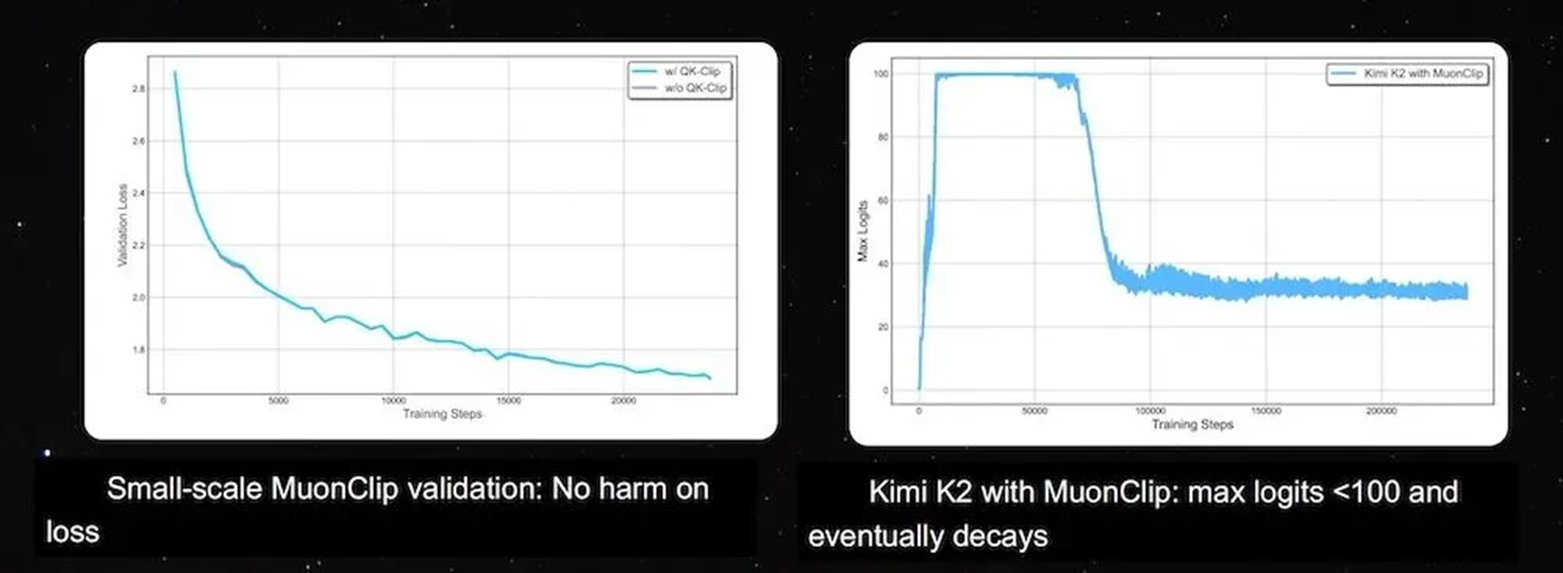
However, Yang also pointed out that while scaling Muon to the training of the trillion-parameter K2 model, the Kimi team encountered stability issues: Logits exploded during training, with maximum values quickly exceeding 1,000, causing the model to diverge.
To address this, the Kimi team proposed the MuonClip optimizer. Yang stated that this method constrains values during the training process by combining Newton-Schulz iteration with a QK-Clip mechanism. In actual training, the max logits of Kimi K2 were controlled within 100 and gradually trended downward, while the model loss remained unaffected, achieving stable training.
He simultaneously mentioned that to make Muon scalable within massive GPU clusters, the Kimi team also designed Distributed Muon. This distributes optimizer states across data-parallel groups and aggregates gradients for calculation only when needed, enhancing memory efficiency and overall training efficiency.
2. Long Context: Kimi Linear Increasing, Decoding Speed by 5 to 6 Times from 128K to 1M
Long Context is the second main pillar of Kimis roadmap.
In this section, Yang highlighted Kimi Linear, a hybrid linear attention architecture based on KDA (Kimi Delta Attention).
Its core idea is to rearrange how attention layers are composed, rather than defaulting all layers to use Full Attention.
Specifically, Kimi Linear adopts a mixed ratio of approximately 3:1 between KDA and Global Attention, reducing memory overhead while maintaining model expressiveness.
Yang mentioned in his speech that Kimi Linear has completed training on a 1.4T token scale and outperforms full attention and other baseline solutions in long context, short context, and reinforcement learning tasks.

The most direct change is reflected in inference efficiency. Within the context range of 128K to 1M, decoding speed can be increased by approximately 5 to 6 times, while maintaining stable performance across different length scenarios.
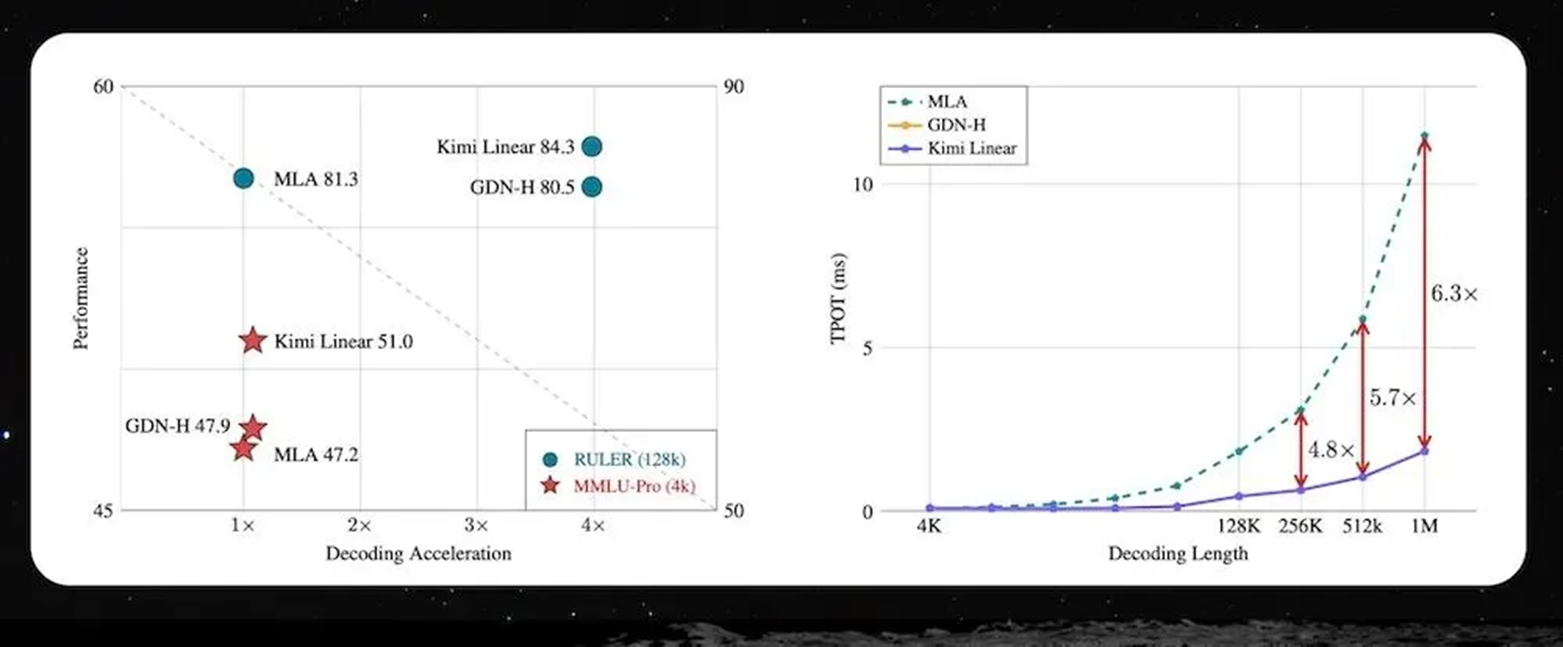
This modification addresses a long-standing issue: as context windows expand, inference costs and latency rise synchronously, making it difficult for long-task capabilities to truly be implemented. Kimi Linear transforms long context from a supported capability into a highly efficiently usable capability.
3. Rewriting Residual Connections, Allowing Each Layer to Retrieve Information More Actively
Compared to optimizers and linear attention, Attention Residuals is another particularly critical attempt in Kimis technical roadmap.
Residual connections are an extremely basic design in deep networks and have been used for about a decade.
Yang mentioned that traditional residual connections use a fixed addition method; as networks deepen, hidden states grow continuously, and deep-level information is easily diluted. The Kimi teams approach is to replace the residual path with dynamic aggregation based on Softmax attention, allowing the model to selectively retrieve information from preceding layers based on input content.
This change shifts information flow from layer-by-layer stacking to on-demand reading, maintaining more stable information representation in deep networks.
In this section, Yang extended the relevant ideas of former OpenAI Chief Scientist Ilya Sutskever at NeurIPS 2024: if a residual connection is viewed as a simplified LSTM expanded along the depth, then Attention can be understood as a further extension of this information channel.
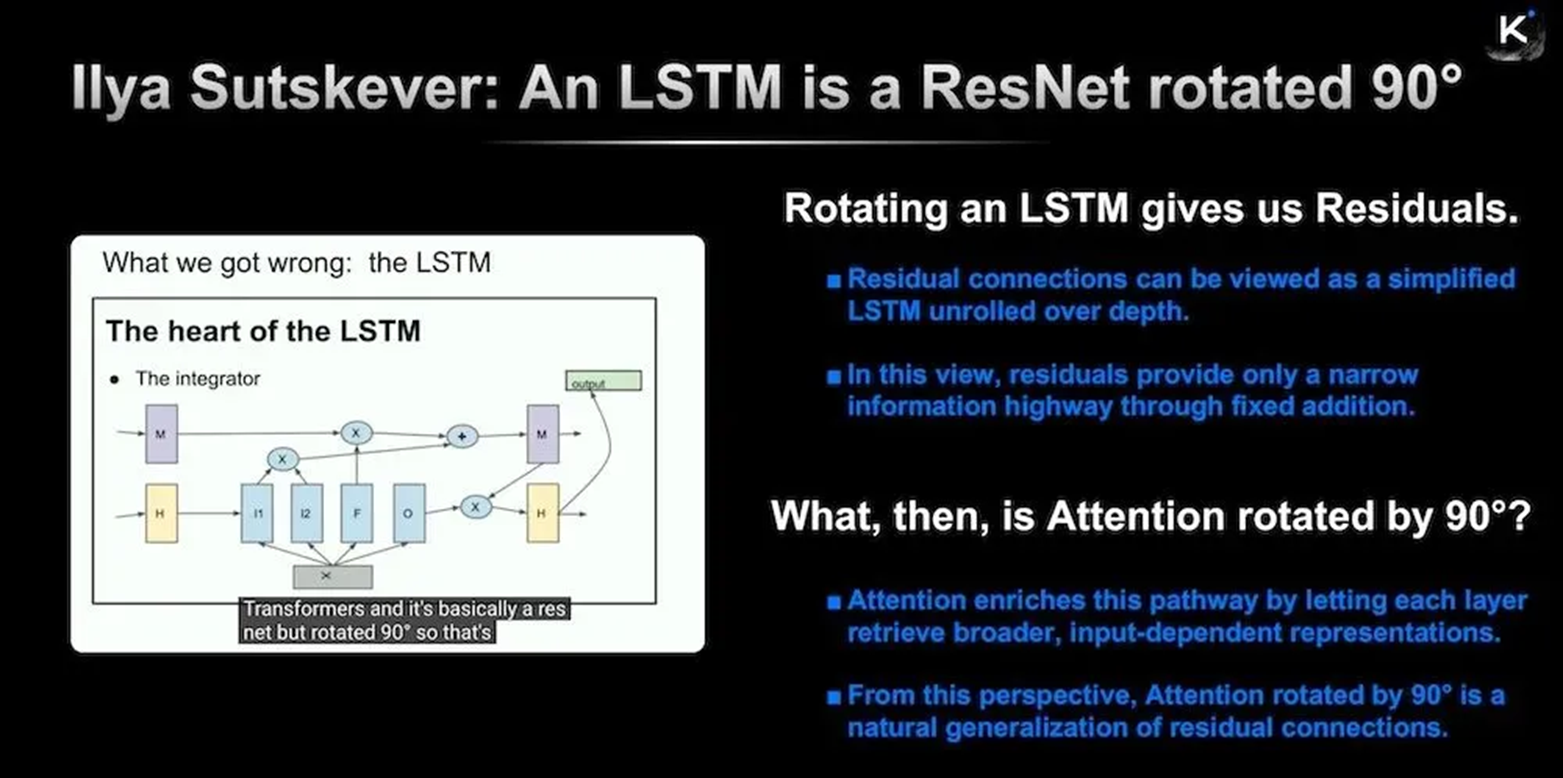
Based on this understanding, Kimi proposed Attention Residuals and has already open-sourced the relevant code and technical reports.
4. Vision Reinforcement Learning Feeds Back into Text Capabilities and Cross-Modality Brings Cognitive Gains
Beyond the models underlying architecture, Yang also shared an important observation regarding cross-modal research directions.
He mentioned that during the native vision-text joint pre-training process, introducing Vision Reinforcement Learning (Vision RL) not only improves the models performance on visual tasks but also reversely enhances pure text capabilities. Ablation study results show that after visual RL training, the models performance on text benchmarks such as MMLU-Pro and GPQA-Diamond improved by approximately 1.7%-2.2%.

Yang believes this indicates that spatial reasoning and visual logic capabilities can be transformed into deeper general cognitive abilities. This work also points toward a direction: the value of multimodal training has shifted from expanding input forms to improving underlying reasoning capabilities.
He also noted that the Kimi team is advancing the first open model with native, joint vision-text capabilities.
5. From Single Agent to Swarm Collaboration: Kimi Bets on Agent Swarms
In the final part of the speech, Yang focused on Agent Swarms.
He mentioned that future agent forms will shift from single agents to cluster systems that can be dynamically generated. Kimi K2.5 introduces Orchestrator, which can create multiple sub-agents based on task requirements and decompose complex tasks into parallel sub-tasks for execution.

These sub-agents can take on different roles, such as AI Researcher, Physics Researcher, and Fact Checker, completing the overall task through division of labor and collaboration.
Yang further added that such systems can cover the complete workflow from input to output, including Input at Scale, Actions at Scale, Orchestration at Scale, and Output at Scale.
As task complexity increases, the efficiency advantage of Agent Swarms over single agents will continue to expand. In experiments, execution time can be shortened by several times.
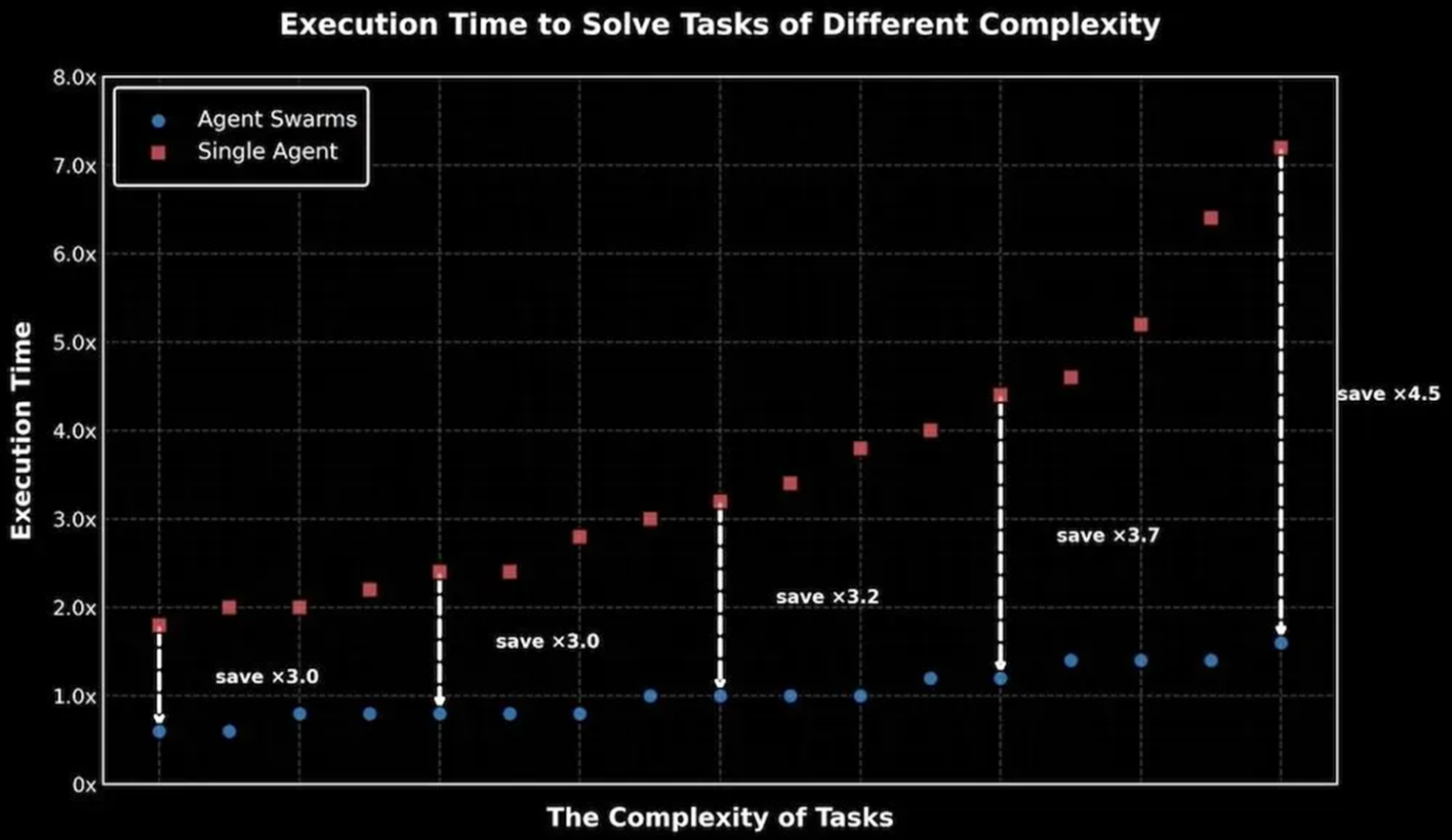
He also pointed out that multi-agent systems are prone to “serial collapse”, where they appear to be multiple agents but actually revert to single-agent execution. To prevent this pseudo-parallelism, Kimi designed parallel reinforcement learning reward mechanisms, including Instantiation reward, Finish reward, and Outcome reward, to guide the model to truly perform task decomposition and parallel execution.
6. Conclusion: Kimi Provides A New Scaling Construction Blueprint
In conclusion, Yang discussed the changes in the AI research paradigm.
He mentioned that in the past, constrained by computing resources, it was often difficult for research to verify the same method across different scales. However, with the establishment of the Scaling Ladder, researchers can conduct more systematic scaling experiments to obtain more reliable conclusions.
This has become the foundation of Kimis current path: Adam was born over 11 years ago, and Kimi advanced it into MuonClip and open-sourced it; Attention was proposed over 8 years ago, and Kimi developed Kimi Linear and open-sourced it; Residual connections have a history of about 10 years, and Kimi further proposed Attention Residuals and open-sourced it.

Overall, the roadmap disclosed by Kimi clearly defines the focus of the next stage of large model competition across three main lines: training efficiency, long context capability, and agent collaborative structures. These three paths are advancing simultaneously and beginning to overlap and reinforce one another.